聊一聊kubernetes operator
前言
微服务兴起,许多业务被部署在了k8s上,大多数业务开发人员日常接触到的基本是build-in资源(ingress service deployment replicaset pod hpa),因此会认为kubernetes(以下简称k8s)是一个设计优秀的paas平台,在k8s中创建资源的人员会被称为yaml工程师🤣。
这么说显得k8s很无聊, 资源只是对象状态的描述,实际执行动作的是k8s的组件(kubelet kube-proxy等),可以说k8s的执行能力足够强大,能在存储、网络、容器上玩出花,你完全可以组织自己的资源格式(crd),利用k8s的能力做自己想做的事,k8s本质上是带有强大执行力的分布式资源管理平台,这种动词-名词分离的解释应该能让你更好地理解k8s。
当今许多对扩展性可用性要求高的项目(TiDB等),更青睐于使用k8s作为基座,这样的深度结合只会让k8s越来越流行。
得益于强大的插件机制,k8s还能自定义资源(crd/cr),自定义controller,自定义api server, 自定义admission webhook,他们让你能有效组合k8s的执行力,做一些有逻辑的事。当下最流行的莫过于玩crd+controller了。
为了让看官更好的了解operator(controller + crd + cr),咱们从k8s两大设计思想:声明式API、控制循环说起。
声明式API
声明式与之相对的是命令式, 命令式顾名思义,让目标按指定命令做事;而声明式则是提供目标一个期望状态,让目标朝期望状态去变更。
看得出来,命令式够简洁,但要花费巨大代价保证命令执行拥有原子性幂等性。
提供期望状态看似冗余,但只要期望状态能被执行者获取到,执行者就能不断尝试着去达成期望状态,过程简单。
而API嘛,指的是k8s apiserver提供的RESTful http接口,创建资源接口需要接收完整的资源期望状态定义, 期望状态指的就是spec中的描述,与之对应的实际状态由执行者(controller)记录在status中。
这也是为啥我们在用kubectl查看资源信息的时候后出现额外的status字段,这实际上是执行者帮我们记录的,专业点的叫法是规约(spec) - 状态(status)分离。比如pod, 除了元信息外,状态从spec和status字段开始展开。
type Pod struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty" protobuf:"bytes,1,opt,name=metadata"`
Spec PodSpec `json:"spec,omitempty" protobuf:"bytes,2,opt,name=spec"`
Status PodStatus `json:"status,omitempty" protobuf:"bytes,3,opt,name=status"`
}
控制循环(control loop)
资源的理想状态存储在k8s的apiserver中,为了让资源由实际状态向期望状态靠拢, 执行者需要监听资源期望状态的增删改事件,这些事件会触发执行者以定时重复执行方式调用对应的handler处理事件, 直到满足期望状态为止,之后执行者再把操作结果记录到实际状态中。
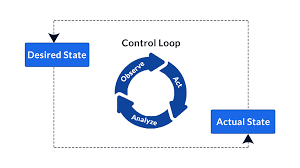
执行者
我们知道,kubelet是k8s自带组件,主要功能通过监听pod期望状态变化事件并做一些事确保本地的pod处于期望状态。
kube-proxy同样也会处理pod的增删改事件,它不断地刷新本机linux网络设备的配置,来确保pod网络通畅。
还有我们常用的deployment、cronJob、statefulset等,它们拥有自己的controller做控制循环,这些controller 运行在组件controller-manager内。
然而不像上面提到的处理k8s原生资源的执行者,这次我们聊的operator,由crd(custom resource definition)、cr(custom resource)、controller组成。
crd用来描述你想创建的资源应该有哪些字段,cr是crd的具体化实现,与对象,对象实例之间区别类似。
我们自己实现的controller控制的目标就是cr, 它的实现原理等同controller-manager中的原生controller:
-
依靠informer的ListAndWatch方法将指定资源的状态缓存在内存中,并不断监控状态变化
-
reconcile方法中的业务逻辑会根据资源的期望状态,对外部世界作出改变,如果处理失败,就重新入队,按某种规则到某个时间继续进入reconcile, 直到处理完成。
-
也可以设置resync period, 全量资源定时入队处理。
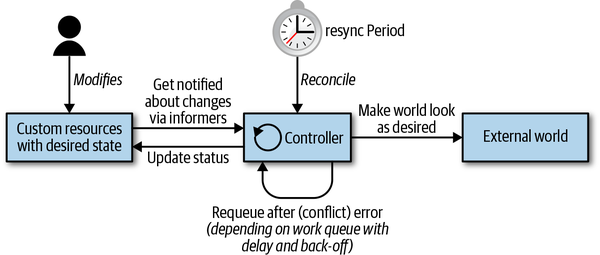
figure-normal (without any classes)
一些细节
时间换空间
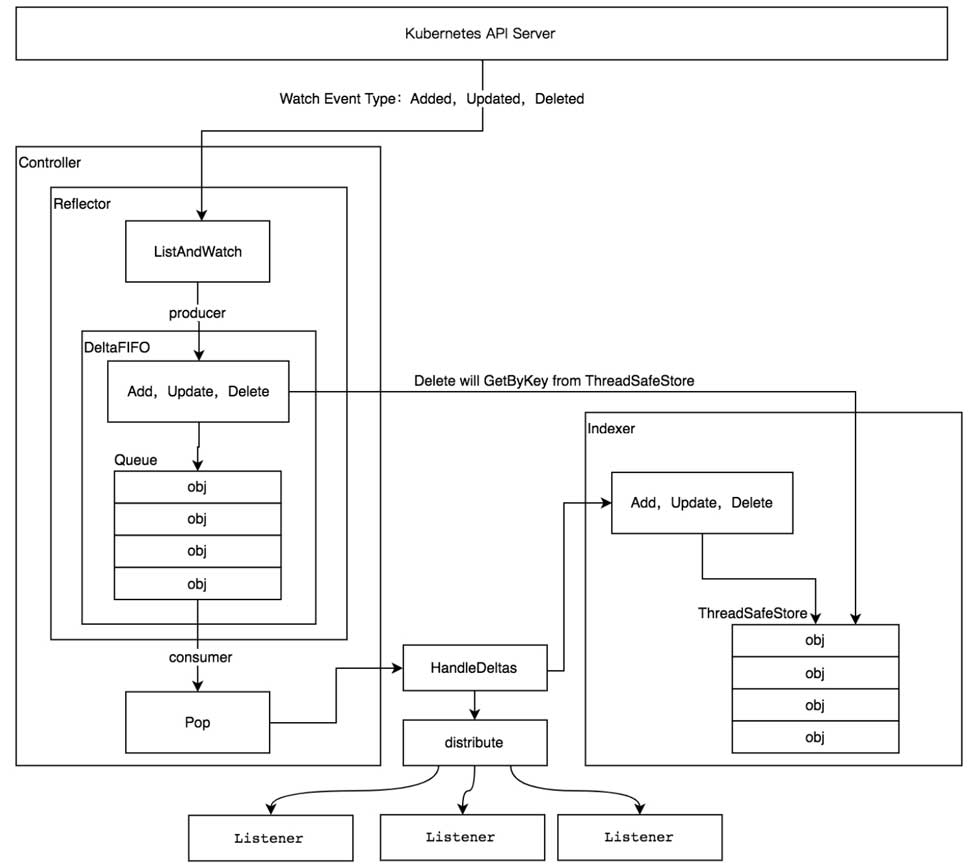
api server是k8s的核心组件,总不能仅仅因为controller要频繁获取资源状态,就让它受高qps压榨延迟变高吧,因此controller在设计时就采用的空间换时间的策略: 把目标资源状态存在内存里,informer再和api server建立http长连接watch事件变化,这样一来,controller在读取资源状态时直接从内存读就行了,变更资源状态时再通过client向api server发送请求。
cache部分由informer实现,这里小提以下它的设计(图在下方):
Reflector: list & watch 资源,写入FIFOFIFO queue: 入队事件动作和对应资源,pop出的数据同时交给Indexer和外部的eventHandlerIndexer(local store): 基于内存的并发安全存储,存储FIFO pop的数据
解耦
通常,informer接收到事件后不会直接执行eventHandler中的业务逻辑,而是将数据丢进queue中,由多个并行的worker处理,妥妥的生产者-消费者模型,避免informer在调用handler时间过长被拖死。
那不加work queue解耦会有什么后果?
通常我们用的是sharedInformer,进程里有多个controller时,用sharedInformerFactory创建出来的Informer只有独立的listener, 其余的reflector和indexer是共享的,原因很简单,多个重复reflector会增加api server负担。而不加work queue时,上一个addHandler还在处理中,listener就将下一个数据写入channel(listener用的无缓冲区channel),而distribute方法又是range listeners的,直接会导致之后的listener无法写入数据,FIFO queue无法被consume, 底层的slice越来越大,直到OOM。
框架生成工具
- code-generator: 底层方式,基本没封装,能帮你了解operator的原始设计。
- kube-builder: 封装好,基本只要关注reconcile的业务逻辑实现。
- operator-sdk: 基于controller-runtime, 和kube-builder大同小异, 未来可能合并。
测试工具
kubebuilder-generatored operator 有自己内嵌的测试框架ginkgo&gomega,这套框架会依赖本地的api-server或者依赖本地etcd二进制文件再创建出来一个新的api server,用作controller-runtime client的请求目标,测试过程按着行为驱动开发(BDD)的方式走,写起来很省心。
练习
实在太懒,我把demo地址放下面了,业务逻辑基本是抄书抄的,带注释带单元测试,感兴趣的可以去看看。
参考
- 《programming kubernetes》
- 《kubernetes源码剖析》
- 《深入剖析kubernetes》