CAN网络设备在k8s集群内的管理方式
背景
车上的CAN网络接口通常在host网络中创建,使用CAN接口的项目需要在host网络中运行,因此可能会产生网络栈资源使用冲突,导致项目启动失败,所以需要使用某种技术能让容器网络中的项目访问CAN网络设备。
已知开源方案
这两种方案基于k8s device plugin监听pod的期望资源并分配实际资源。
yaml例如:
apiVersion: v1
kind: Pod
metadata:
name: demo-pod
spec:
containers:
- name: demo-container-1
image: k8s.gcr.io/pause:2.0
resources:
limits:
shankisme.com/can: 1 //max is 1
如果某pod配置了指定资源,就将CAN的netns设置成该pod的netns,两个项目间的区别仅仅在于容器运行时一个只支持docker,另一个只支持containerd。
问题
-
没有管理好CAN的生命周期,当CAN所在的netns被删除时,CAN也会被删除,需要CAN相关的驱动或守护进程兜底,重新创建出新的CAN接口。
-
CAN接口资源是唯一的,意味着使用CAN的项目只能有一个副本,deployment滚动更新时需要保证老pod稳定运行,不能移除CAN,又要保证新pod拿到CAN达到healthy状态才能完成滚动更新,直接导致死锁。
一般来说k8s device plugin适合分配像gpu、cpu、内存这类分配数可大于1的整数计算资源,而CAN网络接口pod内存在即可,和数量无关,所以基于k8s device plugin的方案不合适。
方案
平滑升级项目版本是有必要的,k8s deployment的滚动更新必然要求同时有多个CAN,单纯移动CAN的想法似乎应该被抛弃。
流量转发
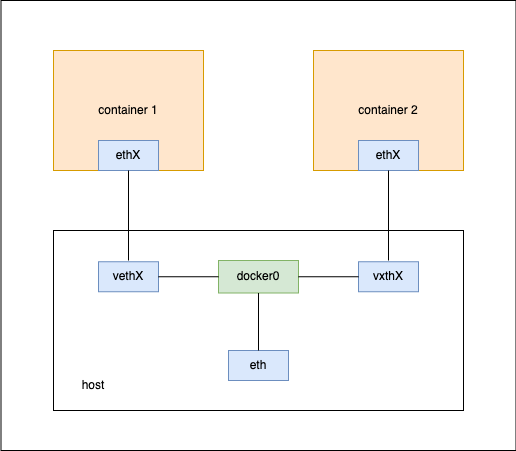
学习docker网络原理的时候,我们会了解到一些特殊的网络设备:veth pair、bridge。
docker的默认网络模式bridge,使用docker0(bridge网络设备)作为host的ethX与其他netns的ethX流量转发中枢,使用veth为容器网络提供ethX接口与外界通信。
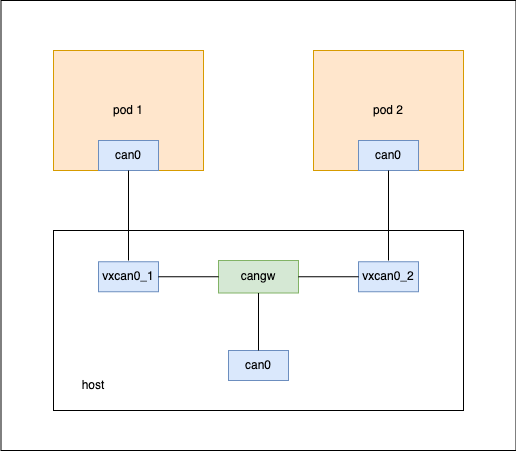
CAN网络设备也有类似的网桥cangw和连接两个netns的vxcan实现上面的流量转发方案, 不过区别是bridge根据ip转发,cangw是分发相同流量。
环境要求
-
linux should support can kernel module(
sudo modprobe canto check and load) -
linux should support vxcan kernel module(
sudo modprobe vxcanto check and load) -
linux should support can-gw kernel module(
sudo modprobe can-gwto check and load) -
安装can-utils
-
ip link 支持 vxcan type,否则更新iproute2
等价shell命令
比如host网络CAN流量转发到pod1:
// 创建vxcan pair: vxcan0_1 and vxcan00_1
ip link add vxcan0_1 type vxcan peer name vxcan00_1
// 将vxcan00_1移到pod1的netns内
ip link set vxcan00_1 netns <pod1ContainerPid>
// up vxcan0_1
ip link set vxcan0_1 up
// 将pod1内的vxcan00_1改名,改成can0
nsenter -t <pod1ContainerPid> -n ip link set vxcan00_1 name can0
// up can0 in pod1
nsenter -t <pod1ContainerPid> -n ip link set can0 up
// 将host的can0读出流量转发到vxcan0_1
cangw -A -s can0 -d vxcan0_1 -e
// 将vxcan0_1写入流量转发到can0
cangw -A -s vxcan0_1 -d can0 -e
使用k8s controller通知pod创建事件
既然基于vxcan和cangw能够为多个容器创建CAN网络设备,并且不需要关心设备数量的问题,咱只需要使用某种标记给pod打上,在labeld pod创建时,controller就能知道需要给哪些pod创建CAN网络设备并分发流量。
也为了方便list这些label,打算用label: shankisme.com/net_device: can 作为pod标记。
// controller.go
var (
targetPodLabel = map[string]string{"shankisme.com/net_device": "can"}
)
type PodController struct {
client.Client
scheme *runtime.Scheme
}
func initAndStartController(cfg *rest.Config, scheme *runtime.Scheme) {
mgr, err := manager.New(cfg, manager.Options{
Scheme: scheme,
})
if err != nil {
klog.Fatalf("unable to set up manager, err: %v", err)
}
c, err := controller.New("pod-controller", mgr, controller.Options{
Reconciler: &PodController{
Client: mgr.GetClient(),
scheme: mgr.GetScheme(),
},
})
if err != nil {
klog.Fatal(err)
}
predicateLabelSelector, err := predicate.LabelSelectorPredicate(metav1.LabelSelector{
MatchLabels: targetPodLabel,
})
if err != nil {
klog.Fataf("predicate err: ", err)
}
err = c.Watch(
&source.Kind{Type: &corev1.Pod{}},
&handler.EnqueueRequestForObject{},
predicateLabelSelector,
predicate.Funcs{
CreateFunc: func(ce event.CreateEvent) bool {
klog.Infof("pod[name=%s namespace=%s] created. enqueue.", ce.Object.GetName(), ce.Object.GetNamespace())
return true
},
DeleteFunc: func(de event.DeleteEvent) bool {
return false
},
UpdateFunc: func(ue event.UpdateEvent) bool {
return false
},
GenericFunc: func(ge event.GenericEvent) bool {
return false
},
},
)
if err != nil {
klog.Fatalf("controller watch err: ", err)
}
klog.Info("start controller manager...")
if err := mgr.Start(context.Background()); err != nil {
klog.Fatalf("manager start err: %v", err)
}
}
带监听条件的controller实现了,接下来的难点是如何获取container的pid
注意观察启动的pod,在status.containerStatus.container[n]内有个containerID字段:
...
status:
containerStatuses:
- containerID: docker://a4a353497809c3802336f59f444cd1615ef65886460c6aed04f7b2669771796f
image: <image>
imageID: <imageID>
...
containerID由两部分组成:<容器运行时>://<容器运行时管理的容器ID>
pod至少含一个容器,使用容器运行时的客户端,将pod status中的第一个容器的ID,转换成PID,即可根据PID进入pod的netns。
有一些容器运行时client库能帮忙转换containerID到PID:
pod controller的reconcile方法逻辑表示:
// controller.go
var (
requeueInterval = 5 * time.Second
)
func (c *PodController) Reconcile(ctx context.Context, req reconcile.Request) (reconcile.Result, error) {
instance := corev1.Pod{}
c.Client.Get(context.Background(), types.NamespacedName{Name: req.Name, Namespace: req.Namespace}, &instance)
containerRuntime, containerID, err := utils.ResolvePodFirstContainerID(instance)
if err != nil {
klog.Error(err, "requeue.")
return reconcile.Result{RequeueAfter: requeueInterval}, err
}
containerPid, err := container_runtime.GetCilent(containerRuntime).GetPidFromContainerID(containerID)
if err != nil {
klog.Errorf("pod[name=%s] runtime:%s getPidFromContainerID err: %v requeue.", req.Name, containerRuntime, err)
return reconcile.Result{RequeueAfter: requeueInterval}, err
}
if containerPid == 0 {
klog.Errorf("container pid 0, pod[name=%s] requeue.", req.Name)
return reconcile.Result{RequeueAfter: requeueInterval}, err
}
utils.CreateVxcanPairAndAddToCangwRule(containerPid, req.Name, req.Namespace)
if !utils.ExpectedCansExistInContainer(containerPid) {
err = fmt.Errorf("expected CAN not found in container requeue")
klog.Error(err)
return reconcile.Result{RequeueAfter: requeueInterval}, err
}
return reconcile.Result{}, nil
}
daemon pod运行环境和权限
为了执行ip link 和 nsenter, controller应该运行在host netns中,并提供host PID;
为了加载内核模块,创建vxcan、编辑cangw转发规则,需要以特权容器身份运行。以及挂载内核模块所在目录/libs/modules;
为了访问容器运行时,需要挂载它们的sock文件,如访问docker就挂载/var/run/docker.sock;
集群也不是每个节点都有CAN设备的,注意匹配node label;
大致可用的daemonSet就形成了:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: can-allocator
namespace: kube-system
spec:
selector:
matchLabels:
name: can-allocator
template:
metadata:
labels:
name: can-allocator
spec:
priorityClassName: system-node-critical
hostNetwork: true
hostPID: true
nodeSelector:
node-role.kubernetes.io/master: "true"
containers:
- name: can-allocator
image: <image>
securityContext:
privileged: true
volumeMounts:
- name: docker-sock
mountPath: /var/run/docker.sock
- name: modules
mountPath: /lib/modules
imagePullPolicy: IfNotPresent
serviceAccountName: can-allocator-sa
volumes:
- name: docker-sock
hostPath:
path: /var/run/docker.sock
- name: modules
hostPath:
path: /lib/modules
资源生命周期管理
vxcan pair是比较特殊的虚拟网络设备,容器网络中的端点删除时,host中的一端也会被清除,cangw检测到vxcan不存在时会删除相关的转发规则,因此我们几乎只需要关心VXCAN的创建和添加cangw转发规则。
daemon pod创建时
- 加载内核模块vxcan、can-gw
- 清除已存在的vxcan
- 检查目标CAN网络设备是否存在
daemon pod删除时
- 清理所有vxcan, 关联的cange转发规则也会被清除
labeled pod创建时
- daemon pod为labeled pod创建vxcan, 并转发can流量
labeled pod删除时
- netns、vxcan pair、cangw rule会依次被内核清理,不需要daemon pod介入
性能
controller实现watch pod & list pod,核心的添加vxcan和添加cangw转发规则的逻辑是通过语言执行shell命令实现的,所以更像是一个自动化运维项目,不需要考虑项目执行流程上的性能,需要关注的是cangw + vxcan的cpu使用率/负载和转发效率。
cpu负载
4cpu的节点上无labeled pod时执行top:

4cpu的节点上10个labeled pod时执行top:

cpu内核进程负载占比并没有明显区别,说明vxcan+cangw方案的cpu负载很低
转发效率
由于太懒,借用搜索引擎了点相关讨论和实验
- discussion: limitations of cangw –github
- benchmark: CAN gateway timing analysis
- paper: linux CAN bus networking subsystem performance evaluation
- view: disadvantage … little run-time overhead, because of CAN message bridging
参考文章
- https://www.lagerdata.com/articles/forwarding-can-bus-traffic-to-a-docker-container-using-vxcan-on-raspberry-pi
- https://www.spinics.net/lists/linux-can/msg00302.html
- https://developers.redhat.com/blog/2018/10/22/introduction-to-linux-interfaces-for-virtual-networking#vxcan
- https://github.com/linux-can/can-utils/issues/226
- https://www.slideshare.net/wentasah/timing-analysis-of-a-linuxbased-cantocan-gateway
- pdf: SocketCAN mit Docker unter Linux